This article starts at the very beginning of my own and personal story to the cloud and to where I am today in my career: Back in 2015, when I barely knew that something big as “AWS” existed.
Of course, being a tech nerd since I started my career, I knew what “AWS” was and that I also had glimpse at guessing its tremendous power and opportunities, but I was not aware of the details and of the possibilities I would see.
How we started
At that time me and my team had built out a lift and shift solution on EC2 instances, where our product was manually deployed on. We aimed to grow our business, but we knew that this would not be possible without automation. Our product had different automation requirements and we did automate these running the required jobs through the Windows task manager.
Now, as we decided to be able to offer our service to other and accitional customers, we needed to find additional possibilities for automation and better operational support.
The first thing that we did was to move away from manually provisioning EC2 instances towards using Cloudformation for bringing up the instances and all of the required infratructure (VPC, sub-nets, load balancers, etc.). This already helped us a lot towards being able to deliver our solution faster. But we still had these Windows tasks which needed to be set up on the different instances. And this is where we looked at additional services in AWS to be able to replace these windows tasks with other possibilities.
Adding Serverless capabilities to the mix
At that time, we looked at using AWS Lambda and Stepfunctions – where were a “brand new thing” at that time – to be able to automate and orchestrate our workflows. With StepFunctions being really new, we recorded a “This is my architecture” video at re:Invent 2018. To be honest, when we started to look at Lambda and StepFunctions, I personally was not very convinced. Coming from a Windows / Java background, moving orchestration capabilities “outside” the “server” (=EC2 instance) feeld wrong as I had not thought about orchestrated workfloads which could run across multiple infrastructure components before.
Through StepFunctions, we orchestrated retrieving data, starting a new EC2 instance, automatically installing our software on it and then running the required workfload. AWS Lambda helped us in this case to be able to start EC2 instances programatically. At the same time StepFunctions gave us the possibility to get an overview on the current status of the executions through the AWS Console. The integration with CloudWatch, which was already available at that time, allowed us to implement alarms and enabled monitoring of execution time.
During the process of testing and implementing this orchestration, we regularly hit new obstacles – e.g. a specific instance type not being available in an availability zone or a different error while reading data from S3. We often thought about giving up our approach, but moved on after seing the benefits of automation and being less dependend on a specific EC2 instance.
Orchestrating workflows using AWS StepFunctions is way easier today than at the time that I was part of this project. In 2017, there were only minimal possibilities of direct integrations with other AWS Services from AWS StepFunctions (like Lambda). Today, AWS StepFunctions offers more than 200 service integrations, “normal” workflows (which are quite expensive) and “express” workflows.
I have been using StepFunctions in different projects lately, also in my project around building my own online & mobile game using serverless technologies at pegasus-galaxy.net.
How do you orchestrate your serverless workflows?
What are your experiences with AWS Step Functions?
In the last weeks – or already months – I’ve been working together with Christian, also an AWS Community Builder, on our project named “Football Match Center”. Christian has already been writing a lot about our project on LinkedIn:
Today, I want to put the attention on our chosen framework for the UI and the way that we are connecting from the UI to the backend. Our backend in this project is a GraphQL API endpoint hosted on AWS AppSync.
Building our UI in Flutter
Since last year Amplify Flutter includes support for Web and Desktop. As we are looking to reach users both on mobile as also on the desktop, choosing a cross-platform development tool like Flutter seemed to be an obvious choice. Christian and I are a small team, and we want to focus on building a simple UI quickly without the need to implement for multiple platforms and Flutter allows exactly that.
Flutter provides easily extendable widgets that can be used on all major platforms.
Connecting to our GraphQL backend
Our project is not based on an Amplify backend, but on AWS infrastructure written in AWS CDK. This made it rather difficult to use the Amplify Flutter SDK as most of the documentations and blog posts expect you to connect the Amplify SDK with an Amplify backend (which can then include a GraphQL API).
But that’s not only what made it difficult – I also had very little experience with Amplify or the Amplify SDK when starting to work on the connection.
Using the Flutter SDK for Amplify we will be connecting to our Cognito instance for Authentication and to our existing GraphQL endpoint. In this post I am going to look at the GraphQL connection and not on the integration of Cognito as an authentication endpoint.
Setting up Amplify SDK for Flutter can be done through the amplify cli if you are starting a new project.
This will then also create the required amplifyconfiguration.dart and some example code through amplify init.
You can then set up the Amplify SDK for Flutter from within your main widget using this code:
import 'package:amplify_flutter/amplify_flutter.dart';
import 'package:amplify_api/amplify_api.dart';
import 'amplifyconfiguration.dart';
import 'models/ModelProvider.dart';
….
Future<void> _configureAmplify() async {
final api = AmplifyAPI(modelProvider: ModelProvider.instance);
await Amplify.addPlugin(api);
await Amplify.configure(amplifyconfig);
try {
await Amplify.configure(amplifyconfig);
} on AmplifyAlreadyConfiguredException {
safePrint(
'Tried to reconfigure Amplify; this can occur when your app restarts on Android.');
}
}
While this looks easy when reading the documentation (and a lot of very good blog posts), this was rather difficult for me as I was not able to use the amplify init command. Finding out the structure of the “amplifyconfiguration.dart” and the implementation for the “ModelProvider” were my main challenges.
Lately, the related documentation has been updated and it is now easier to work with existing resources.
The Amplify Configuration file
The Amplify Configuration (amplifyconfiguration.dart) configures all of the required Amplify Plugins. In our implementation we started with the GraphQL backend:
This tells the Amplify SDK to talk to a specific API endpoint when the “Amplify.API” is invoked. As far as I understand this Github issue, right now only one API can be queried from a specific Amplify instance.
When using the apiKey to do the authentication with the API, we will need to regularly update the Flutter application as the default API expires after 7 days.
This documentation was not available when we started to work on the project and I have the suspicion that Salih made this happen 🙂 (if not, still THANKS for the help you gave me! 🙂)
The ModelProvider
The ModelProvider should be a generated file, which you can generate from an existing GraphQL API. If you are using a schema that is not managed by Amplify, you will need to use “amplify codegen” based on an existing schema file.
The command expects a schema.graphql to be available in the “root” folder of the Amplify Flutter project. If you execute “amplify codegen models”, required Dart files will be generated in the “lib/models” directory.
The result should be a file similar to this one:
import 'package:amplify_core/amplify_core.dart';
import 'Match.dart';
import 'PaginatedMatches.dart';
import 'PaginatedTeams.dart';
import 'Team.dart';
export 'Match.dart';
export 'PaginatedMatches.dart';
export 'PaginatedTeams.dart';
export 'Team.dart';
class ModelProvider implements ModelProviderInterface {
@override
String version = "4ba35f5f4a47ee16223f0e1f4adace8d";
@override
List<ModelSchema> modelSchemas = [Match.schema, PaginatedMatches.schema, PaginatedTeams.schema, Team.schema];
static final ModelProvider _instance = ModelProvider();
@override
List<ModelSchema> customTypeSchemas = [];
static ModelProvider get instance => _instance;
ModelType getModelTypeByModelName(String modelName) {
switch(modelName) {
case "Match":
return Match.classType;
case "PaginatedMatches":
return PaginatedMatches.classType;
case "PaginatedTeams":
return PaginatedTeams.classType;
case "Team":
return Team.classType;
default:
throw Exception("Failed to find model in model provider for model name: " + modelName);
}
}
}
Querying our GraphQL API
Now that we have been able to connect to our GraphQL AWS AppSync endpoint, we can start querying data.
Luckily, the preparations we made and the Amplify for Flutter SDK provides convenience methods that returned typed data structures that we can directly interact or work with.
You only need to write the GraphQL query that you are interested in and you can directly read data from the endpoint. In my example below I’m creating a Flutter Widget out of the returned elements and then I am adding them to a list of Widgets that I can display in a Column Widget:
Future<List<TeamWidget>> _getMatchesByCountry(String country) async {
List<TeamWidget> teamsWidgetList = [];
try {
String graphQLDocument = '''query ListTeams {
getTeamsByCountry(country: "${country}") {
nextToken
teams {
PK
PrimaryColor
SK
SecondaryColor
TeamName
}
}
}''';
var operation = Amplify.API
.query(request: GraphQLRequest<String>(document: graphQLDocument));
var response = await operation.response;
var data = response.data;
if (data != null) {
Map<String, dynamic> userMap = jsonDecode(data);
List<dynamic> matches = userMap["getTeamsByCountry"]["teams"];
matches.forEach((element) {
if (element != null) {
if (element["id"] == null) {
element["id"] = "rnd-id";
}
var match = Team.fromJson(element);
teamsWidgetList.add(TeamWidget(match));
}
});
}
} on ApiException catch (e) {
print('Query failed: $e');
}
return teamsWidgetList;
}
Just today, we have merged a feature that adds a “subscription” to our AppSync endpoint – as as next step we plan to integrate this within the Amplify Flutter Application which will then allow us to implement notifications to the end users. Unfortunately, the Amplify SDK for Flutter does not yet support in-app messaging as it does for Javascript.
What YOU learned – and what I learned
Through this blog post you have learned how to connect an Flutter application with Amplify using the Flutter SDK for Amplify. You have also got to know our project, the “Football Match Center” – and you’ve seen some code to make your start easier when talking to a GraphQL (AppSync) backend.
I have learned to work with the Amplify for Flutter SDK and also how code generators can help you to speed up your implementation. I’ve also gained experiences in accessing data from AppSync and on working with the returned data in Flutter.
Unfortunately, I have also found out that using the Flutter SDK for Amplify I can right now not implement the planned in-app notifications that Christian and I wanted to build for our Football Match Center to notify users about upcoming or recently completed games.
At re:Invent 2022 AWS announced Amazon CodeCatalyst and as you might have read on my blog or seen on my YouTube Channel I have been playing around with the service a lot. A few days ago, Brian asked me a few interesting questions, one of them being:
What’s the diff between CodeCatalyst and AppComposer?
Lately we had a Community Builders session with the Amazon CodeCatalyst team and similar questions came up in regards to comparing CodeCatalyst with other, already existing services.
And to be honest, the amount of AWS services that are related to building, managing or deploying software projects on AWS has grown a lot in the last years and it gets difficult to keep an overview of how these services play together and which tool has which functionality.
In this post we are aiming to compare and place CodeCatalyst in relation to other (new or already existing) AWS Services. We are also going to look at missing functionalities that are currently available in other services but not in CodeCatalyst.
Please be aware that these are all our personal opinions and based on our own understanding – some of it being assumptions.
This post was Co-Authored with AWS Community Hero Brian Tarbox – Thanks for your support!
AWS Services that we are going to compare CodeCatalyst with:
Amplify was released at re:Invent 2018 and has since then been improved gradually.
Amplify is a complete solution that lets frontend web and mobile developers easily build, ship, and host full-stack applications on AWS, with the flexibility to leverage the breadth of AWS services as use cases evolve.
With that AWS positions Amplify as a service that is able to reduce the heavy lifting on web or mobile developers that want to get started on AWS. AWS has extended Amplify into being a service that offers nearly all building blocks required as part of your SDLC process. It does not offer source code repositories, but CI/CD capabilities. You are able to configure the CI/CD pipeline and also provide your own build images. With the release of Amplify Studio in 2021 AWS extended the capabilities to include a “No-Code/Low-Code” capability that allows rapid-prototyping for web and mobile applications. The target audience for Amplify are Front-End and Mobile developers with no to minimal experience on AWS.
Application Composer
This is a new AWS service announced at re:Invent 2022 mainly focused on “rapid prototyping” helping you to quickly “paint” serverless applications – build our your architecture out with visualizations, Application Composer will create the required “starting code” (Cloudformation, but also Lambda code) in the background. As output you get a project in code that you can then commit to a Git repository or deploy out to AWS. Application composer enables Serverless developers to quickly prototype serverless applications and convert them into code that can then be used as a starting point for your project. Application composer does not provide Source Code management or CI/CD capabilities.
The service, which reached GA on March 8th of 2023, points at developers starting new serverless projects that quickly want to get both an architecture diagram as well as a starting point for further developments.
App Runner
This is a AWS service announced in 2021 and it can be used to build, deploy and run web applications based on containerized workloads. It allows you to stay focused on your application with the service taking responsibility to provision and host your application. It also takes care of creating a container from your source code. You can connect App Runner either to your source code management system or to a container registry.
Beanstalk
This is one of the “ancient” AWS services – it was announced in 2011 and has since then been around. In the community I have more than once heard that “Beanstalk is dead” and not being actively developed anymore, but still – it works and can be used to provision your web applications. At the same time, you will still be able to access the infrastructure that is required to host your service. The “message” is similar to App Runner – it helps developers to focus on writing business code and ignore the deployment strategy. Beanstalk supports Java, .NET, PHP, Node.js, Python, Ruby, Go and Docker web applications. In order to use Beanstalk, you will need to upload a source bundle – it is not possible to connect beanstalk automatically to a Git repository, but you can update the source bundle automatically using APIs.
We treat these services in one group as they belong together from a strategic point of view. They have been around for a few years and the teams that built these are now involved in CodeCatalyst. CodeCatalyst partly uses them “under the hood”. CodeCommit is a managed git hosting, CodeBuild is a managed “build” system, CodeStar is a “project management” tool. CodePipeline allows combining multiple CodeBuild steps to form a pipeline. CDK Pipelines integrate with CodePipeline today. With CodeArtifact users are able to store artifacts and software packages.
All of these services are tied to a specific AWS Account and live within the AWS Console. This has forced organizations and AWS customers to create “toolchain accounts” that centrally host these services. These tools might be considered as building blocks rather than a full solution.
CodeCatalyst
As we are comparing the other services with CodeCatalyst, we also need to define what CodeCatalyst is: a new AWS service announced at re:Invent 2022 that will cover the full lifecycle of product development on AWS, starting from the source up to the deployment part. It is an “All-in-one” solution to help you build software on AWS efficiently. You can manage your planning and issue tracking in it as well as your source code and your CI/CD workflows. I have a few introduction videos recorded available on YouTube. CodeCatalyst lives “off” the AWS Console and this means that you do not need to be logged in to use it – and it can access multiple AWS accounts by an integrated authorization process.
Proton
This is a AWS service announced in 2020 – and AWS describes Proton as a service to allow central teams to build and provide central infrastructure components that can easily be shared with users while at the same time maintaining the integrity of the deployed infrastructure. With that, the tool is focused on infrastructure provisioning (=deployment) pipelines. Proton allows the central “platform team” to provide templates to be used by application teams – with only minor changes or configurations to it.
Which problem(s) does CodeCatalyst address?
CodeCatalyst addresses the need of developers or of development teams that need to cover all parts of the product life cycle or parts of it with a tool natively built on AWS. It can be used for issue management and planning as well as source code management. It has natively built CI/CD capabilities with workflows for Continuous Integration and Deployment. CodeCatalyst offers an opinionated solution for addressing software development best practices on AWS. It also allows online-editing of source code with the Dev Environments and supports the management with reports on resources and workflows managed as part of CodeCatalyst.With Blue Prints it allows developers to quickly start a new project and reduces the time to get a new project started. It can be seen as an opinionated approach to development.
So, how does CodeCatalyst relate to the other services?
Out of the six services we looked at, a few can at first glance not compete or be compared with CodeCatalyst as they target a different audience or address different problems as CodeCatalyst:
Proton – does not help with building or deploying code, it is targeted towards “composing” an application from various pieces. As such, it might be part of a solution but not the whole solution
Application Composer – while this service can be used to do a rapid-prototyping for serverless architectures, it does not allow source code management or deployment of the built architecture. I hope that we will see Application Composer as a new option for starting off a new project in CodeCatalyst going forward
Beanstalk – is not a “developer focused” tool as it comes with pre-build environments and CI/CD pipelines and expects you to manage the source code externally
Based on this, the services we want to look at in more details are:
While Amplify allows to build CI/CD pipelines and manage deployments for both Front-End and Back-End components of an application, the pipelines and deployments are limited to the services supported by Amplify and the capabilities of the automatically generated CI/CD pipeline. There is not much flexibility to adjust the pipelines. In addition to that, Amplify does not allow you to store your source code or to manage your software project. It has no build-in issue management or tracking system.
With Amplify Studio and the corresponding tutorials you get the possibility to quickly get started on specific use cases. This is not as flexible as the CodeCatalyst Blue Prints but gets you started pretty quickly. Amplify Studio is awesome as a “low-code”, getting you started tool – it allows you to quickly build full-stack applications through a User Interface and for that use case it is definitely better than CodeCatalyst. At the Berlin Summit in 2022 I attended a Live Demo of Rene Brandle and was amazed by the functionalities.
Amplify Studio lives “outside” the AWS Console in the same way as CodeCatalyst and it also requires an AWS account to be connected for deployments. Each Amplify project can be connected to one AWS account. This is more flexible in CodeCatalyst.
Still, Amplify misses a lot of things that are required for an end-to-end “DevOps” tool to manage all processes and requirements of an agile software development project.
Comparing CodeCatalyst to the Code* services (CodePipeline / CodeCommit / CodeBuild / CodeStar / CodeArtifact) feels a bit like comparing a Tesla Model 3 with Karl Benz’ Patent-Motorwagen 🙂
The Code* services feel complex to use, although they provide similar functionality than CodeCatalyst if you combine them together. They are “building blocks” that you as a developer can use to build “your own version” of an integrated Developer Toolchain.
In addition to that they live in a specific AWS account, as mentioned above, which makes the handling of access complicated and requires you to have an IAM user that is allowed to access them.
The user interface and possible integrations are minimal and feel “developer unfriendly”. CodeCommit has the CodeGuru Reviewer integration which is currently not available in CodeCatalyst.
CodeBuild (and with that CodePipeline) is very slow in bringing up new, fresh “build instances” – so starting a new pipeline execution can take minutes which is bad for developer productivity. This is something that CodeCatalyst is addressing with the “lambda” execution environment.
Summary, takeaways and our wishes
As per the messaging, blog posts and announcements from AWS around CodeCatalyst, we believe that the service today aims to offer an opinionated tool for development teams that want to practice “You build it, you run it” – in line with the DevOps mentality. It also means that AWS shows the courage to not only give builders a tool at hand but also “influences” what they build with Blue Prints that include best practices. The vision for CodeCatalyst however could be even more than that: a tool, powered by KI capabilities that empowers builders to efficiently develop and build high quality software by reducing the manual work and efforts through automation.
However, CodeCatalyst is not yet there and it’s going to take some time and effort from the team to reach this.
Wishes for Developer Tooling in General
This post has shown that AWS offers a lot of different possibilities to handle software projects on AWS. We made clear that all of the available tools serve a different purpose and target a different audience. While Amplify focusses on Web or Mobile developer and Application Composer targets Serverless developers, Code Catalyst takes a more generalist approach.
Overall, the “Developer Tools” landscape on AWS needs:
More and better guidance on WHEN to use WHICH service
Better “HOW TOS” instead of hard-to-read documentation or specification
Wishes for CodeCatalyst
Compiling a wish-list for CodeCatalyst can be a big effort as there are still a lot of features that we would like to see. We’ll touch on a few ones here:
General
Single Sign On without Builder ID – Okta/Ping/etc.
Other regions support
Allow “Open Source” projects
Issues / Tracking
Epics
Roadmap / Timeline
Integration with Workflows & Automation
Source
Import projects from Git providers
Automations on Pull Request
CodeGuru
Security Review
Best Practice Review
Support of pre-commit hooks when editing online
Verifications, linting, etc. automated
Workflows
More triggers (e.g. by PR, by schedule, by API)
Conditional Steps
Manual approvals
App Store / Play Store deploy actions
Projen Action
Better integration with AWS services
Import existing CodePipelines
Pipeline as Code – CDKPipelines like option to create workflows from code
What wishes do YOU have for Code Catalyst? What is your “most hated” or “most loved” feature today?
A few weeks ago, on december 1st 2022, Werner Vogels announced Amazon CodeCatalyst. I’ve previously shared my initial thoughts and findings in a blog post. In this post, I’m going to share a few more findings and insights into using Amazon CodeCatalyst and will also see if any of my wishes from the wishlist for CI/CD on AWS have been resolved with CodeCatalyst.
What I have been playing around with…
CodeCatalyst login page
One of my personal projects that I am working on together with a few friends is pegasus-galaxy.net and the CI/CD pipeline that I had built with CDK Pipelines (that I also presented at re:Invent 2022) was the first one to try to move over. In context, we’re talking about a Flutter application for Web running behind CloudFront, deployed using CDK.
I decided to try CodeCatalyst out and go “all in” – and that means moving the code from Bitbucket into CodeCatalyst as well as setting up the other users in CodeCatalyst and moving the workflows (=CI/CD pipelines) over to CodeCatalyst.
CodeCatalyst Menu
In this article I am going to go through each of the sections in CodeCatalyst and will share my experiences, thoughts and findings.
Where I have ideas on how to improve the day-to-day work with the tool, will try to share that.
Before going into details, lets start with the most important thing:
Amazon CodeCatalyst works very well and reliable and the current version of the service is a great foundation for moving all of your CI/CD and development practices to AWS.
The CodeCatalyst team has been very supportive on re:Post, so if you have a question, feel free to ask it there!
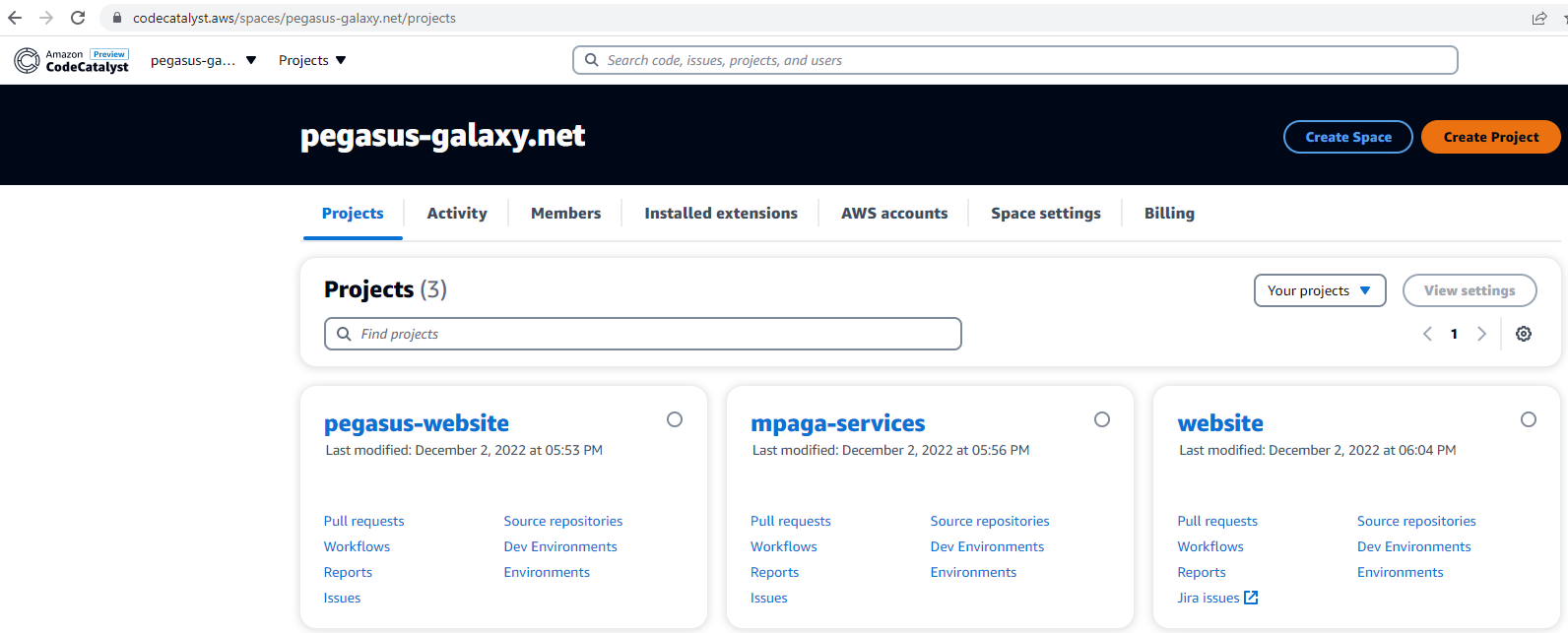
CodeCatalyst Overview – Spaces and Projects
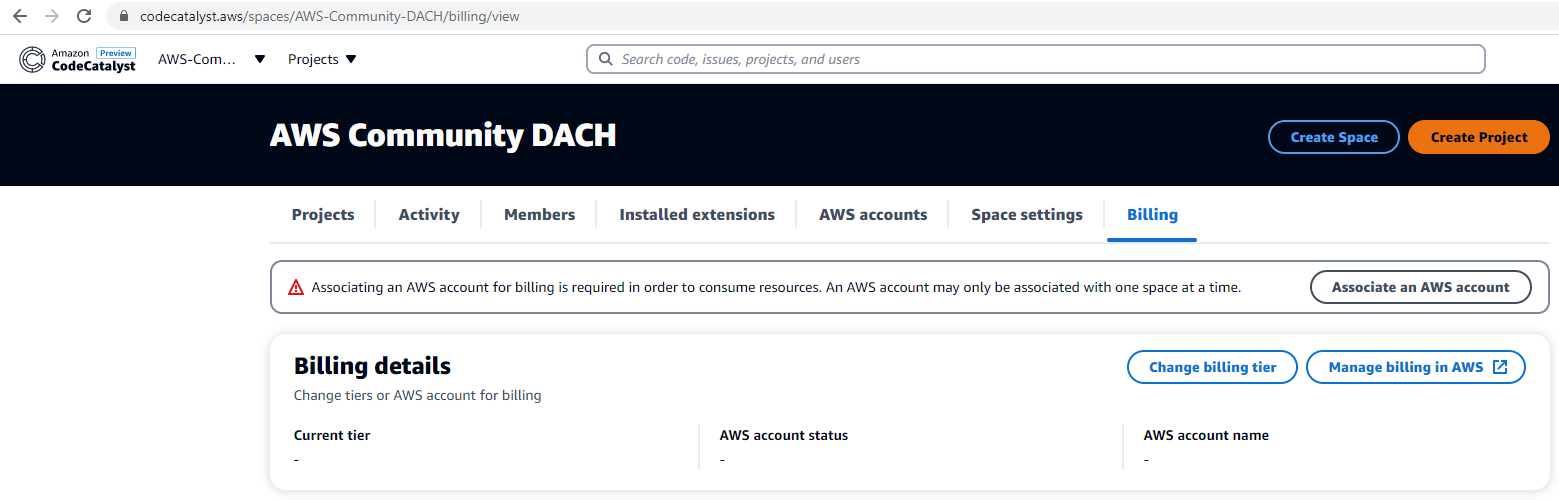
Spaces are the “Top-Level” option to organize your CodeCatalyst account. You will need to associate an AWS Account for billing used AWS resources. Each AWS (billing) account can be associated only with one CodeCatalyst Space.
CodeCatalyst Spaces Billing page
While this seems like a limitation as you will need to create a different billing account for a 2nd space, I can right now not see an impact for my day to day work. For anything that I run on the same AWS account, I would assume that using a project within the same space should be good.
You can manage Projects, Members and AWS Account connections on the space page. In the “extensions”, CodeCatalyst currently allows a connection only to the JIRA Cloud. I would expect that additional 3rd party extensions will be supported in the GA version of CodeCatalyst.
Projects Overview and options
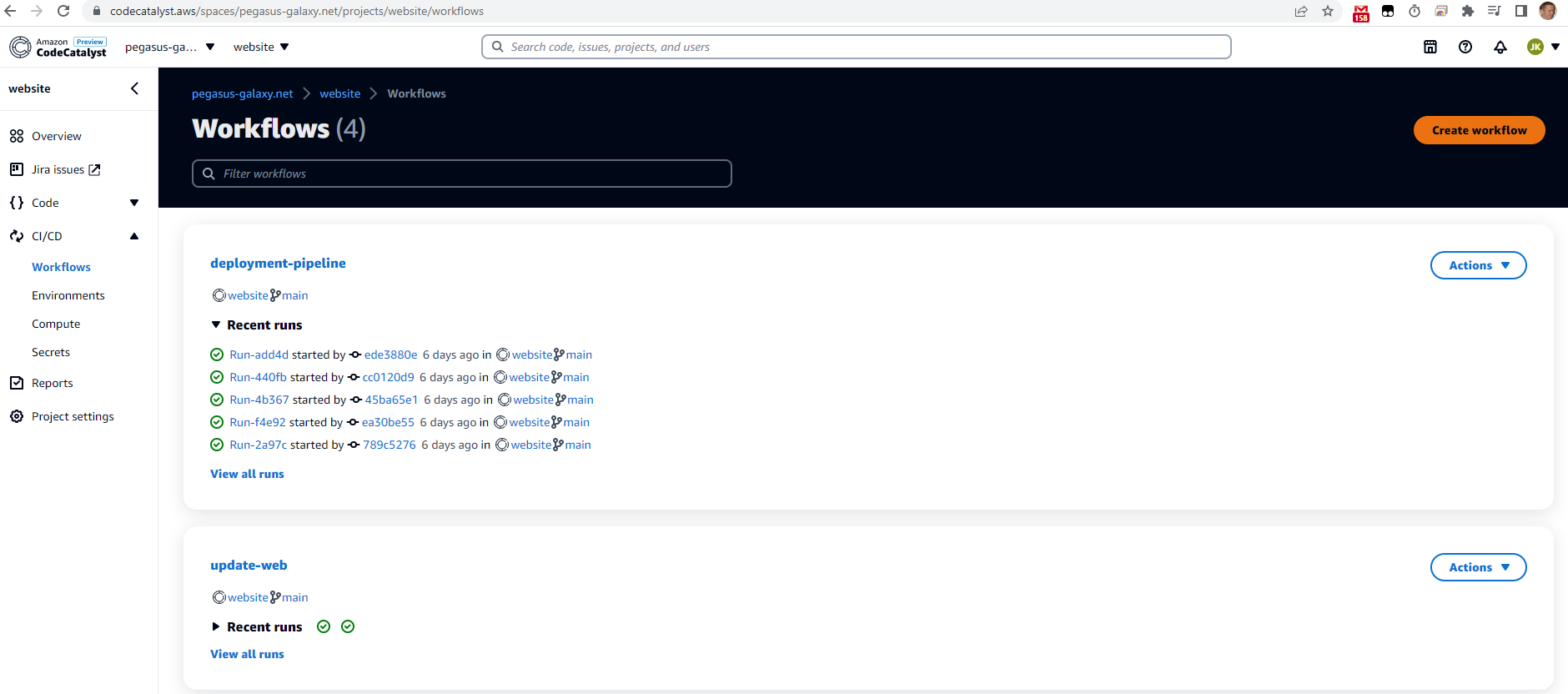
A project is a “unit of work” in your product or software that you are building. Within projects, you can manage issues, manage your code repositories, execute workflows (CI/CD) and review report results.
Projects are associated to a Space – and you can create as much projects in a Space as you want. You can add team members to a project, that are not able to access all projects in the space. Unfortunately I have not yet found an option to “hide” projects from Team members that are added on the Space itself.
Managing issues / tickets
CodeCatalyst currently provides two options to manage your issues or tasks: 1) Link to JIRA Cloud Project 2) Internal issue management
If you use the option to link to a JIRA cloud project, the “issues” link is replaced by a link to your JIRA Cloud project.
Internal issue management
The internal issue management system currently offers everything that is required for a simple Kanban workflow. You can create issues, add them to a backlog or a Kanban board, assign them to project members and track their current status. I personally think that the current functionalities are good enough for small teams and simple projects – I’m actually already working with it in a small project and will add additional feedback as soon as I gain more experience.
Code
Within the “Source” part of a project, you can manage source repositories or connections to source repositories in Github. I expect that other providers will be added going forward (e.g. Gitlab, CodeCommit, Bitbucket, …). You can also manage pull requests and approvals – I was only able to test this using internal source repositories, not using a linked repository.
The last option – the Dev Environments – is the most exciting functionality – it gives you the possibility to host development environments (similar to Gitpod) on AWS using Cloud9 but also, and this is really cool, using Visual Studio or JetBrains IDEs. When using that option, the IDE on your local PC is only the “presentation layer”, the source code is stored and run on an AWS instance and the IDE uses remote connectivity to talk to the Dev Environment in the background.
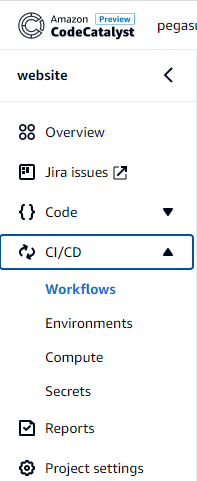
CI/CD
CodeCatalyst currently uses the same approach as Github Actions to manage your workflows or CI/CD pipelines – you are able to manage your Workflows using YAML files. The syntax is simple and understandable. There is a minimal set of Actions available as part of the preview. You are also able to use existing Github Actions as part of your workflow.
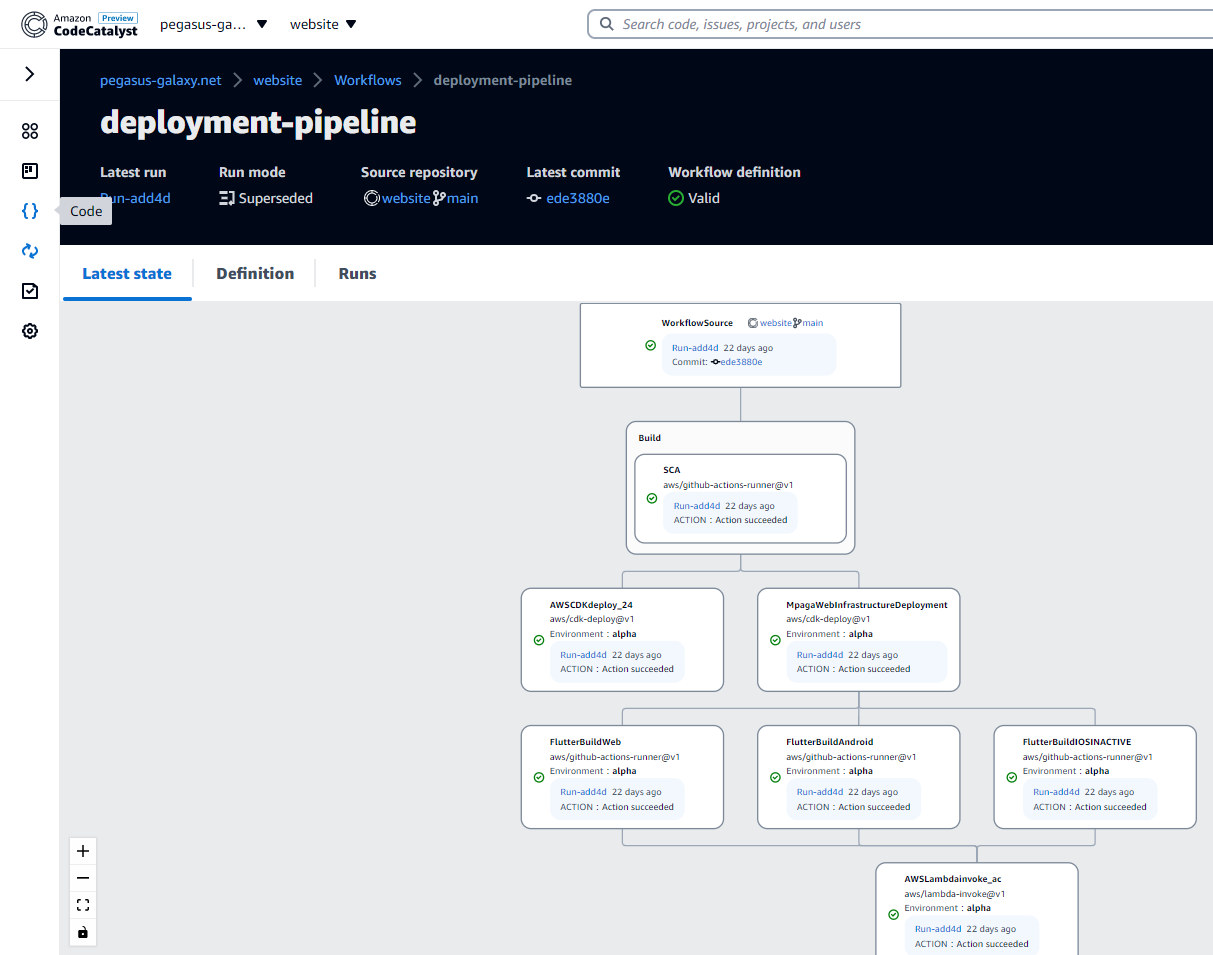
Workflow overview in CodeCatalyst
The workflow functionality is very powerful. In my tests I have not yet been able to test all parts of the capabilities. Workflows can be defined for certain directories, for certain triggers or branches. Test reports will be exposed in the “reports” functionality.
CodeCatalyst offers a graphical overview for workflows and alows to edit them in the UI, too. This functionaly works pretty well and helps to quickly get you started building your first workflow in CodeCatalyst.
I’ll need to test the workflows more to be able to give additional insights into how good or bad they are currently running. My simple pipeline that builds a Flutter Application, deploys my Infrastructure as Code using CDK and then publishes the new version of the Flutter app runs without problems.
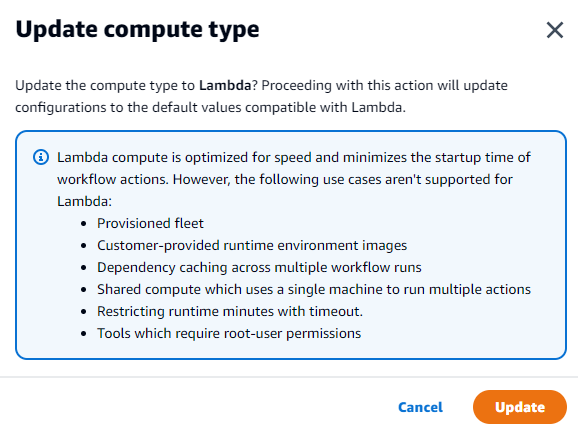
One of my main concerns so far is the execution time, however the team has been working on a possibility to use Lambda as an execution environment. This option however does not yet support the execution of Github actions and also has some other limitations.
The other features that are part of the “CI/CD” – Environments, Compute and Secrets – I did not have time to play around with this. If you have any experiences with it, please add your thoughts in a comment to this article!
Reports
The reports today only suport test reports. I have not used the functionality enough to assess this, but I am sure that the CodeCatalyst team is going to add additional reporting options going forward.
Things I like most about CodeCatalyst (Preview) after 6 weeks of usage
Just a short list of things that I already like: – Integration of Github Actions as workflow actions – Managing workflows using UI & code
Things I miss in CodeCatalyst (Preview) after 6 weeks of usage
– macOS builds (e.g. for Flutter iOS apps) are still not possible – granular permissions for workflow and Pull Request triggers – and….
Let’s talk about Open Source Projects
Right now there is no option to share a project or a repository that is hosted within CodeCatalyst as an Open Source project. This is really a limitation if you want to use CodeCatalyst for Open Source project – or if I would like to share a CodeCatalyst repository with example workflows. I hope this functionality will be added soon.
Wrap up and next steps for me with CodeCatalyst
I need to admit – writing this post took longer than expected 🙂 I wanted to publish it before christmas and now it seems to be a bit “late” already as I am sure that a lot of you have made your own experiences with CodeCatalyst today – please SHARE your findings with me – links of Blogs that you have written or other content you have created, I am eager to consume it!
My next steps with CodeCatalyst
I am working on migrating my project pegasus-galaxy.net completely to CodeCatalyst and collaborate with my team on it there. With that, I will be able to proof CodeCatalyst in a “real world” application that it is “multi-platform” application – using Flutter for Web, Android and iOS – and a Serverless AWS based backend. If you’re interested to join this project, please do not hesitate to reach out – skills that we need right now: AppSync, DynamoDB and development/software engineering (Flutter, Typescript, Java, or Node?)
As we are now in the post:Invent phase of 2022 and over 10 days have passed since re:Invent 2022 in Las Vegas was concluded, it’s time for a lot of re:Cap Blog posts and events. I’ve read so many of those “major announcments” articles that I’ve decided to write a different type of re:Cap for myself this year: Sharing a few stories from my 10+ days in Las Vegas, as they are as equally important as the technical announcements made by AWS.
Indeed, it was a great conference with a lot of learnings and a lot of very interesting sessions. I focused on Chalk Talks, Builder’s sessions and events (like Gameday) as these are not recorded.
Making new friends before re:Invent kicks off
My flight this year got moved from Saturday to Friday, so I had one more day to get over Jet-Lag. On Friday, I spend a good time shopping and besides that met with Oliver vor dinner. On saturday morning (early morning!), I looked at the AWS Community Builders Slack and found out that Traian set up a “spontanous breakfast” for the Jet-lagged folks – and I ended up sitting over two hours with different parties, having fun, chatting and getting to know people. It was exciting to meet Rafael, who had been our Solutions Architect for a while, for the first time in person – without planning it 🙂 It was also great to meet Heitor in person – the person that owns the Lambda Power Tools at AWS. His talk is now on Youtube and I would encourage you to listen to it if you are interested in Open Source.
The rest of the saturday I spend with Markus, who shared so much Las Vegas knowledge with me that I think my brain is still burning – and I would not dare to claim remembering more than half of what we discussed – but it was a great saturday which ended with meeting Philipp for dinner at “The Cheasecake factory”.
I kicked off the sunday with a lot of excitement about my very first talk at re:Invent – final technical check in the “Speaker Ready Room” for my slide deck! That needed to be early morning, because afterwards I had planned to go out hiking with fellow AWS Community Builders.
Hiking across time zones and cultures
Definately one of my highlights this year: The ever first AWS Community Builders pre:Invent Hiking Trip!
Thanks to everyone that joined – Oliver, Richard, Jenn, Ganesh, Traian, Pubudu, Niklas. It was great to see how we supported each other, had great conversations and all managed to get across different challenges we had to fight!
Thank you Oliver (and kreuzwerker) for the amazing video. Traian, you’re my hero. Congratulations on finishing off the hike with us with. Thats an achievement noone can take away.
It was fascinating to meet you all for the first time and notice that we get a long well, without ever meeting before. That’s the power of the AWS community!
We got back at 6pm, after a over 5 hours hike, just in time to get our AWS re:Invent badges and to meet other AWS Community Builders from around the globe for a great dinner. Lilly & Jason – thanks for joining us, that really made me happy!
Welcome to re:Invent
Kicking off re:Invent with a GameDay with a great team an Jeff Barr
I decided to kick off my re:Invent on Monday with a GameDay – which is a fascinating opportunity for gamified learning. On sunday, during our hike, I had aligned with Niklas to form a team together – and the other two team members, JaeJun and Martin, we met in the morning. We had great fun, ended up 4th even tho Jeff Barr distracted us for some time as we won him on our table with a quizz. It was great meeting him in person – and I can tell you: He is a human as we are, even if his Newsblog is legendary 🙂
Meeting people from the AWS Community
I had so much great hours in Las Vegas – thanks for the time spend together, everyone that I’ve met – Stefanie, Oliver, Manuel, Mike, Stefan, Philipp, Markus, Thorsten – and others – from the german community.
Finally met Danielle and Matt in person. Another of my highlights.
The Community Builders Mixer and the User Group Leader Mixer where both great events to get to know each other better and network with great people from everywhere in the world. I met so many people that I had been interacting with in written (Slack, Twitter, LinkedIn) – it was a blast for myself.
Famous Jenga-game with AWS Heros – so much fun!
Famous Jenga-game with AWS Heros – so much fun!
Speaking at re:Invent 2022 – my DevChat
As I’ve already shared before this year I had the opportunity to speak at re:Invent – COM307 – Using CDK pipelines (in Java) to build a multi-platform Flutter application
Thanks for everyone that made this possible: Ernesto, Shantavia, Lilly, Jason, Maria! It was my biggest honor to share my experiences and my open source initiative. Looking forward to keep sharing knowledge!
Announcing Amazon CodeCatalyst
With the announcement of Amazon CodeCatalyst the conference brought for me a new service that I am eager to use and try out as I am very much interested in CI/CD on AWS. This was for me definately the most exciting anouncement of re:Invent 2022 and I had a lot of interest to talk to the service team, product managers and others after the service had been announced. I’m looking forward to share more about that as I get to play around with it more.
Flying out
On saturday my trip to re:Invent was over and it ended as my re:Invent trip began: meeting AWS interested persons at the airport (Thanks Maria for the introduction!) and with great conversations with Oliver on the way back to Frankfurt.
Thanks to everyone that I met and talked to at re:Invent 2022 – you really made this conference be a different one for me than it was before.
I’m looking forward to hopefully meet all of you again in 2023!